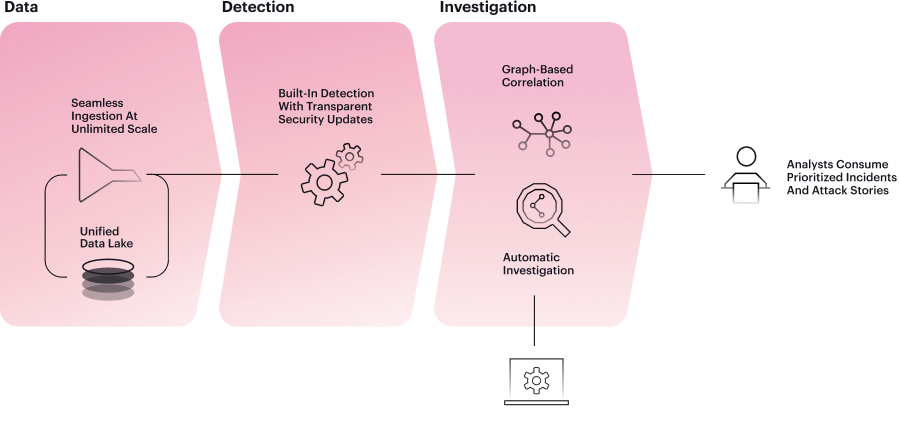
DATA
Integrating with your existing workflows
Sending accurate data that has already been enriched and correlated from Hunters to your SOAR or workflow software ensures a speedy response.
DATA
.png?width=335&height=671&name=Group%20632106%20(3).png)
Replace SIEM/UEBA projects that take 6 months to onboard and another 6 months to train
Separate storage from compute costs, allowing you to ingest as much data as you want with no surprise costs
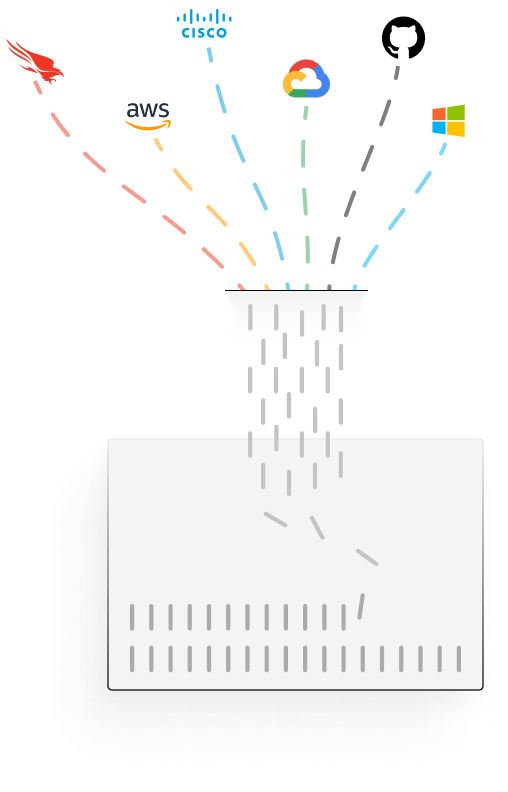
Collect and normalize logs from your existing IT and security stack
It’s your data, so you choose where it sits

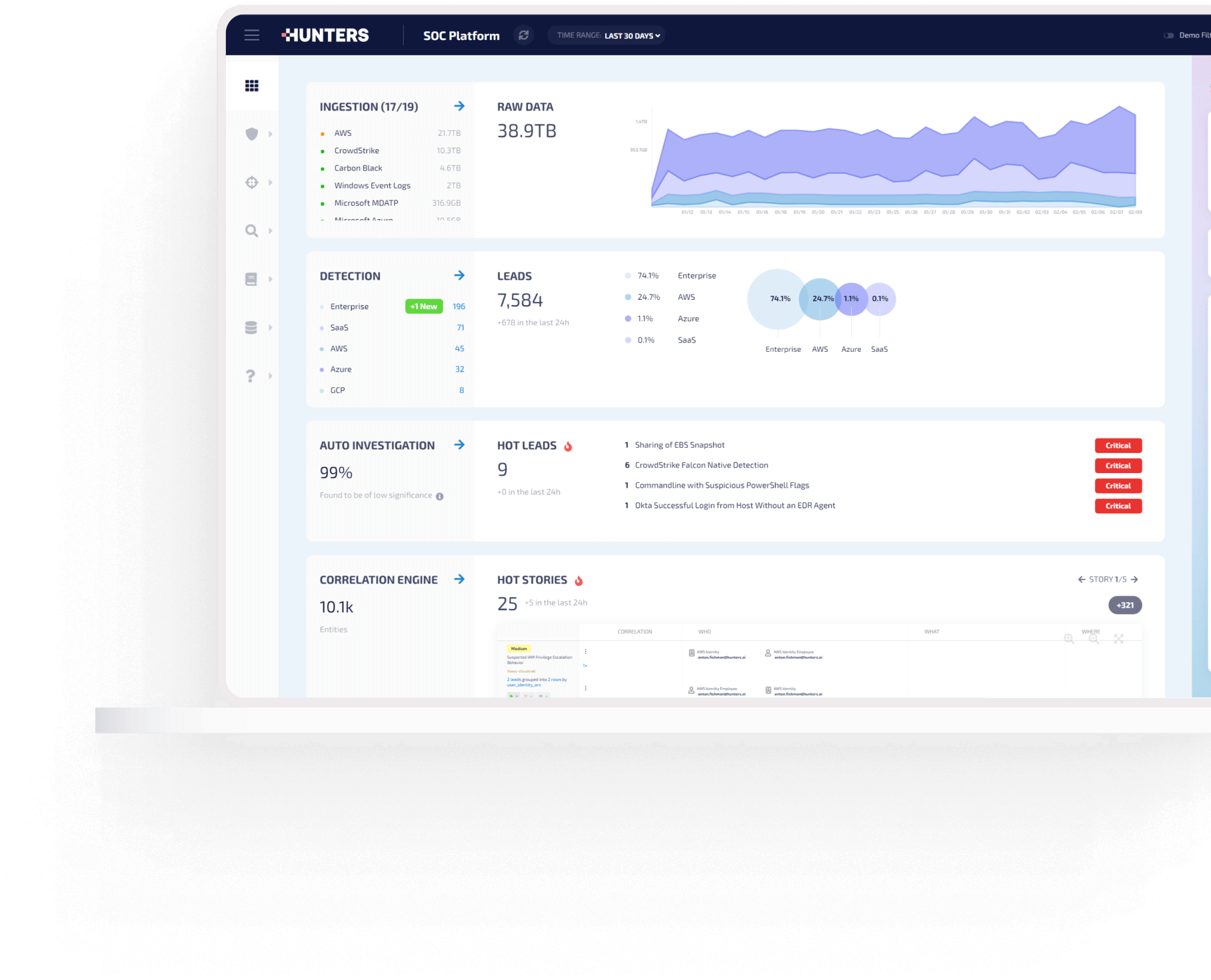
DETECTION

Always up-to-date
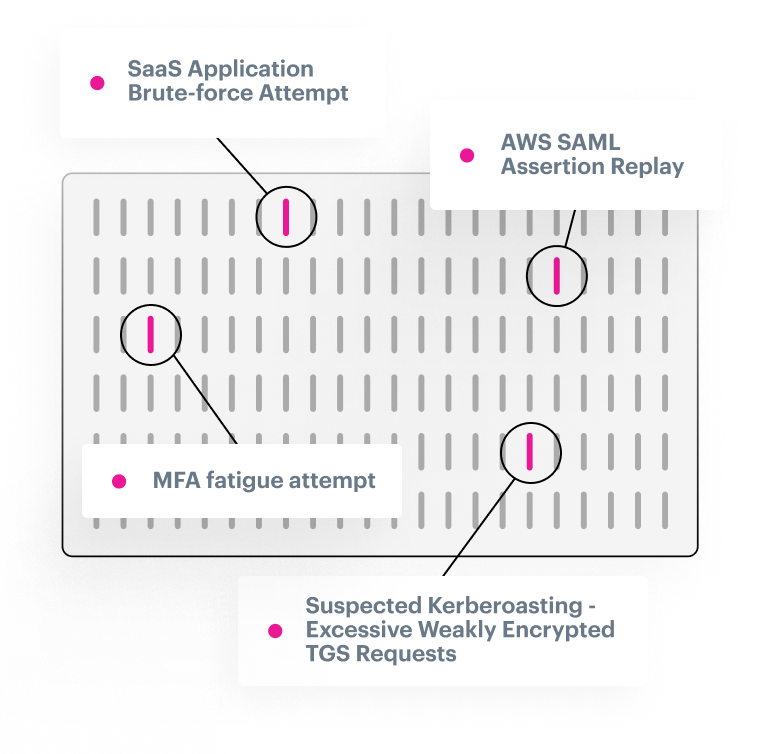
Expert detection rules that are constantly updated and pre-verified on real-world data
Never added noise
Expertly researched and tuned detectors that are wildly efficient right out-of-the-box
Mapped to MITRE
Instantly understand your detection coverage based on the MITRE ATT&CK framework
Customizable detections
Build your own detectors specific to your organization or industry
INVESTIGATION
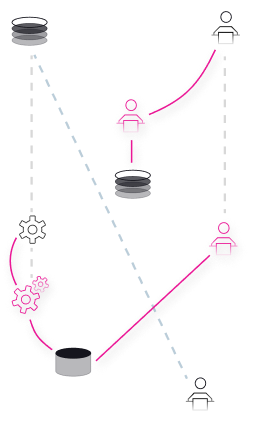
Connect strong and weak signals across the entire attack surface with graph-based correlation
Auto-enrichment across internal and external data sources removes manual querying
Easily visualize connected incidents and malicious movement through your organization
Dynamic and customizable scoring and prioritization amplifies signals and reduces noise
Use a lightning-fast search bar to see if a known IOC has been in your environment
Alerts are clustered based on similar threat context using proprietary logic to streamline analyst workflow


Sending accurate data that has already been enriched and correlated from Hunters to your SOAR or workflow software ensures a speedy response.
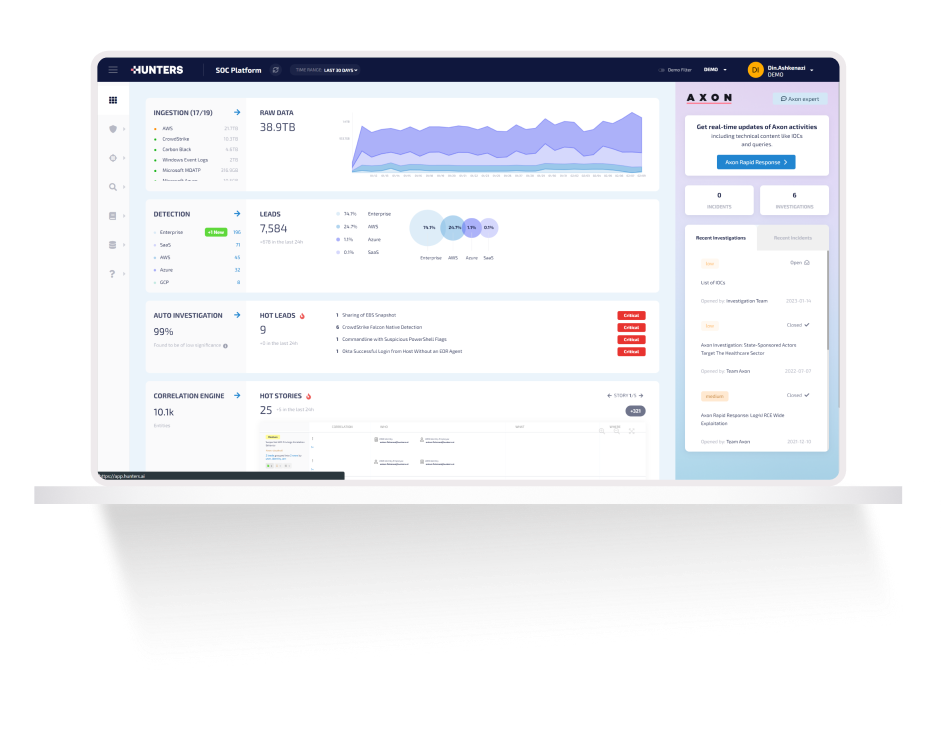
Our in-house expert team of threat hunters are called into action for rapid response to emerging threats, proactive threat hunting and on-demand investigations.